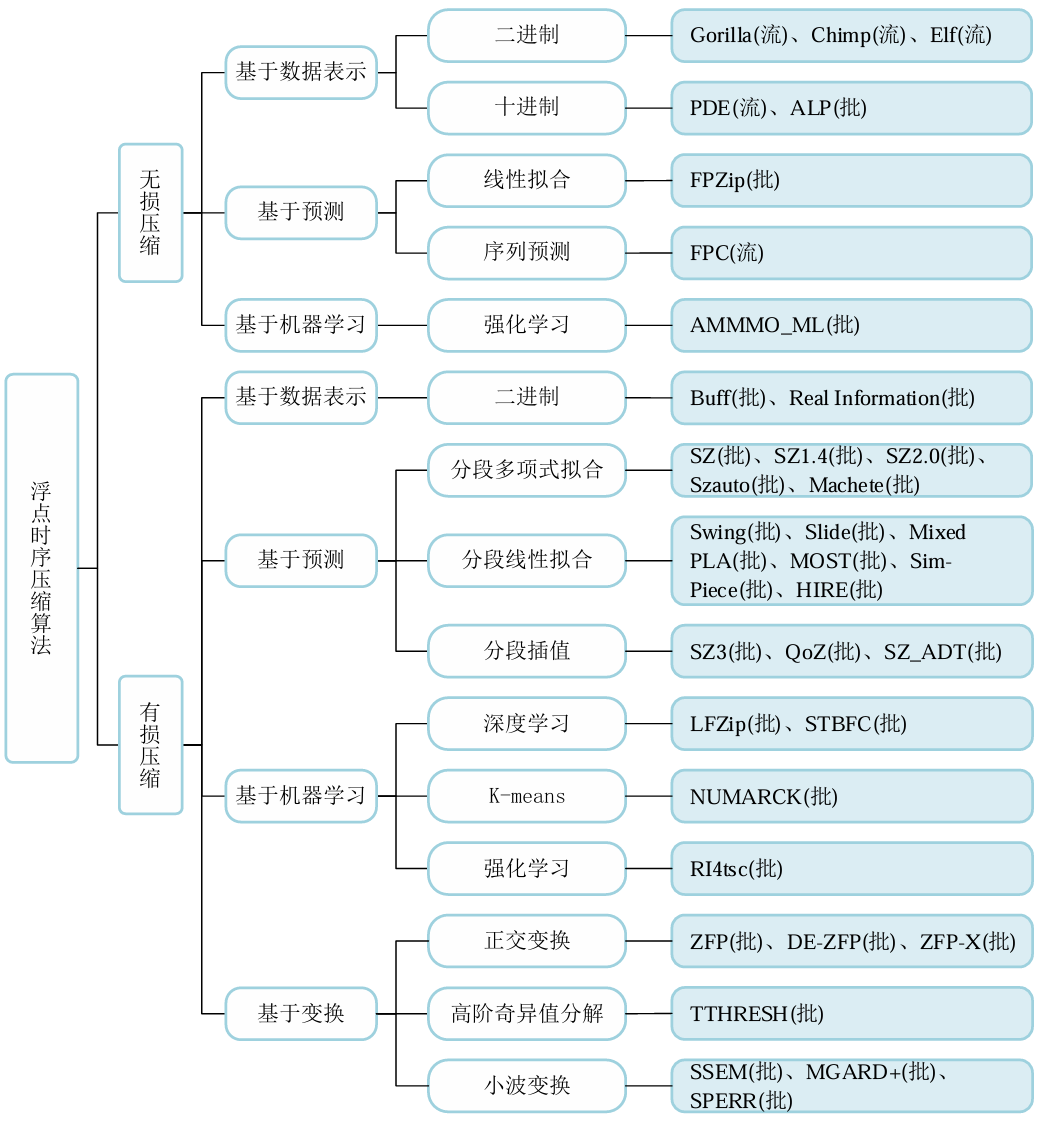
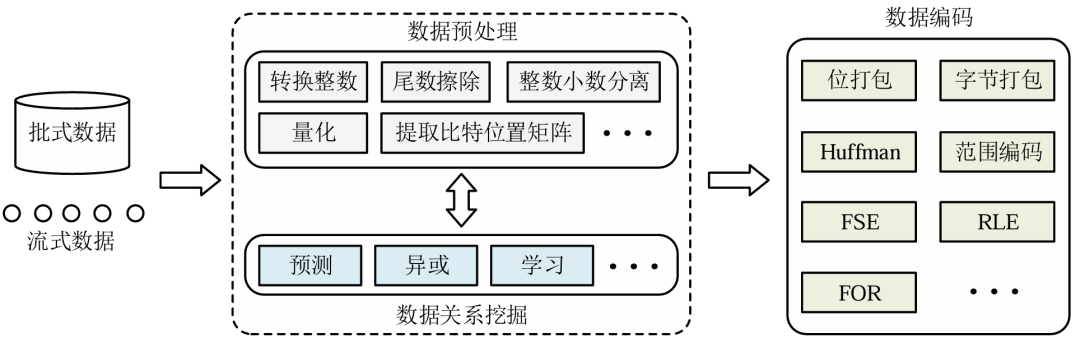
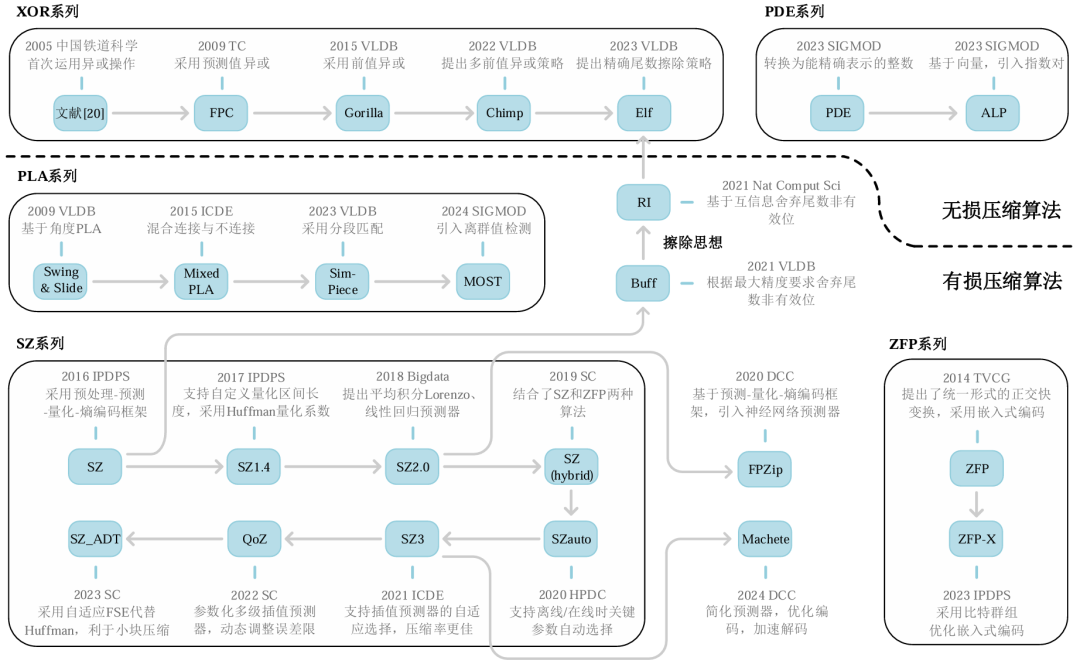
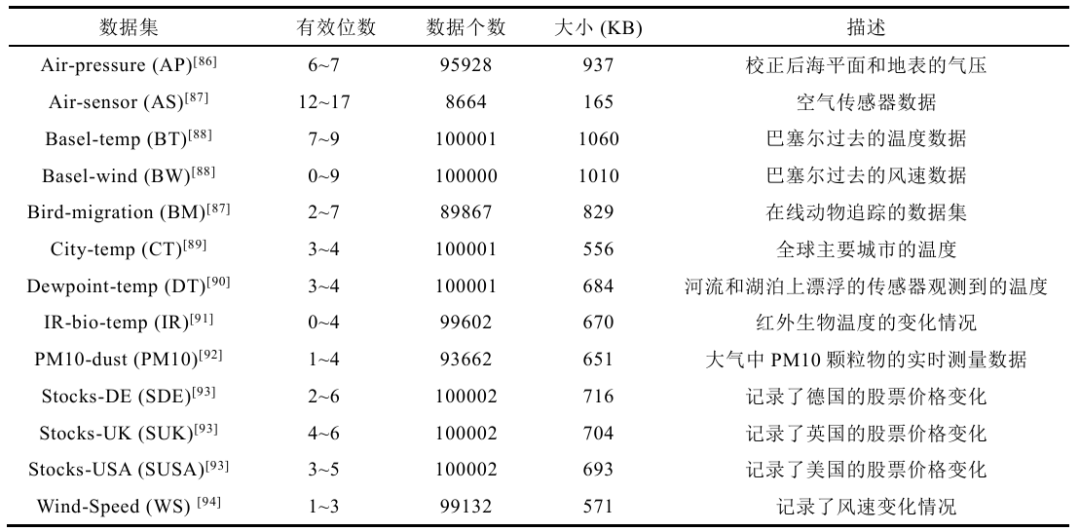
物联网技术的发展产生了海量的浮点时序数据, 这给存储和传输带来了巨大挑战。为此, 浮点时序数据压缩变得至关重要。其根据数据可逆性可以分为有损和无损压缩。此外,实时性应用的需求催生了流式压缩算法。先前的时序压缩综述论文存在梳理不全面、脉络不清晰、分类标准单一、未归纳较新的具有代表性算法等问题。本次为大家带来重庆大学Start Lab在软件学报最新收录的论文《浮点时序数据压缩综述》。时序数据(Time Series,TS)是数据点按时间顺序递增的有界序列或无界序列,根据数据维度不同,主要分为单时序数据(Univariate Time Series,UTS)和多时序数据(Multivariate Time Series,MTS)。时序数据的时间戳通常采用 Delta编码或者 Delta-of-Delta 编码进行压缩,在时间间隔较小的情况下有着较好的压缩率。在针对浮点数值类型的压缩中,为了衡量其效果,通常会考虑3个度量指标:压缩率、压缩/解压缩时间和精度。其中精度用于有损压缩衡量重构时间序列相对于原始时间序列的保真度,反映压缩的质量,具体包括逐点误差、范围误差、均方误差、均方根误差、峰值信噪比、精度增益等指标。我们从三个维度对现有算法进行分类:(1)可逆性;(2)算法框架; (3) 流批处理特征。具体代表性算法的分类如下图所示。在可逆压缩中,压缩和解压缩操作是完全可逆的,不会导致数据丢失。而不可逆压缩引入了信息损失,解压缩后的重构数据不完全等同于原始数据。依据设计动机,不同的算法框架能够在满足相应需求的前提下,实现不同的压缩率和性能。基于数据表示的压缩算法可以分为基于二进制的压缩算法和基于十进制的压缩算法,且常见于无损浮点时序压缩中。前者基于连续数值之间的差异通常会比较小这一假设,但有时候,十进制浮点数值的轻微变化会引起底层二进制表示的巨大差异。后者不存这一问题,主要思想是将浮点数乘以10的n次幂转换为整数来编码。 基于预测的压缩算法通常利用统计学模型来分析历史数据并进行预测。对于有损压缩而言,目前主流的方法为分段函数拟合,其中又包括分段多项式拟合(Piecewise Polynomial Approximation,PPA)和分段线性拟合(Piecewise Linear Approximation,PLA)。基于机器学习的压缩算法通常结合了无监督学习、深度学习、强化学习等其他学习方式,能够更好地理解并保留数据的重要特征,显著改善数据压缩的效果。基于变换的压缩算法将数据从原始域转换到另一域,通常是一组基底函数(变换)的域,来寻找更紧凑的表示。常见有离散小波变换、高阶奇异值分解等。批式/流式浮点数据压缩算法通常由数据预处理、数据关系挖掘和数据编码三大部分组成,如下图所示。有些算法在挖掘数据关系之后应用预处理操作(如SZ先预测,再量化);也有算法先执行数据预处理操作然后再挖掘数据关系(如Elf先执行尾数擦除,然后执行异或运算);还有算法跳过数据预处理,直接进行关系挖掘(如Gorilla直接执行异或运算)。但所有算法都包含数据编码阶段。数据预处理和数据关系挖掘本质上是找到数据的另一种表示,方便后续数据编码。我们整理了部分代表性系列的算法,列出了这些算法的主要发展脉络,如下图所示,主要包括无损压缩算法中的XOR系列和PDE系列,以及有损压缩算法中的PLA系列、SZ系列和ZFP系列。其中,实线箭头表示,所指算法在之前算法的基础上进行改进实现了较大的提升,或者体现着类似的思想并在时间上有承接关系。(1)数据集。为了对比不同的压缩算法,我们选用了表1中的12个单时序数据集。此外为了清晰地对比不同的方法,我们整理汇总了2个多时序数据集在部分有损压缩算法中的对比结果,数据集信息如表2所示。(2)环境。我们的实验是在一台配备了Windows 11,第11代英特尔(R)核心(TM) i5-11400@2.60 GHz CPU和32GB内存的个人电脑上进行的,采用C++语言,其中gcc版本13.2.0,cmake版本3.28.6。从表3中可以看出ALP、Elf算法在浮点类型数据的压缩率有着相当显著的优势。Gorilla和Chimp128算法压缩时只需进行简单的XOR算法以及一些标志位的判断,因此二者压缩速度较快。我们对有损压缩算法在不同的误差限进行实验,结果如表4所示。最新Machete算法压缩率最为出色。Buff在给出精度与元数据精度一致的情况下可以做到无损压缩。SZ_ADT所使用的自适应FSE更适用于小文件压缩,相比与SZ2,在不降低压缩效果的情况下,显著提高了压缩和解压效率。我们同样汇总了部分代表性有损压缩算法在多时序数据集上的实验结果。如表5所示,SZ3在不同误差限精度下有着最佳的压缩率。ZFP的变换机制加上软件缓存策略,使其压缩和解压效率相对更好。数据压缩的主要目的是为了加快数据传输和减少数据存储。在传输场景中,浮点数据的压缩技术能够显著减少传输数据量,提高传输效率,降低传输延迟,同时确保数据的完整性和准确性。在存储场景中,压缩算法的主要目标是减少数据的存储需求,提高数据存取效率,同时保持数据的关键特征和质量。随着时序数据爆发式的增长和IoT行业蓬勃的发展,浮点时序压缩将扮演越来越重要的角色。我们从多维时序数据压缩、不解压查询与应用、软硬件结合、特殊浮点型压缩四个角度展望未来的研究方向,希望对后续的相关工作有所启发。我们对历年来的时序数据压缩算法按有损压缩和无损压缩进行划分,并进一步区分不同的算法框架,包括基于数据表示、基于预测、基于机器学习、基于变换等,同时对流式与批式的压缩特征进行归纳。然后对各种压缩算法的设计思路进行深入分析,并给出各算法的发展脉络图。接着结合实验比较各类算法的优势与不足。最后总结算法常见的应用场景,并对未来研究进行展望。| 重庆大学计算机技术专业2023级硕士生,重庆大学Start Lab团队成员。 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|朱明辉
校稿|李 政
编辑|朱明辉
审核|李瑞远
审核|杨广超
关注公众号,回复“软件学报_浮点压缩综述”获取论文、源码






0 条评论