流批一体化
开篇导语
流批一体化(Stream-batch Integration)是一项重要的数据处理技术,在多个领域中具有广泛的应用潜力。尽管现有的流处理和批处理方法能够解决各自领域的问题,但是单独使用它们难以满足全面、实时的数据分析需求,同时还会带来开发、运维成本高昂的问题。流批一体化技术通过将实时数据流和批处理数据相结合,不仅能够实现更加全面、准确和实时的数据分析能力,从而为企业提供更加深入的洞察和决策支持,还能显著减少开发成本和运维成本。流批一体化技术在大规模数据分析[1]、实时风险控制、个性化推荐系统和实时监控与反欺诈[2][3]等场景中都发挥着关键作用。因此,数据流批一体化技术对于数据处理领域具有重要意义,能够推动业务的创新和发展。
InfoBox:
中文名:流批一体化
外文名:Stream-batch Integration
学科:数据库,数据管理
实质:流批一体化是指将数据流和数据批处理的计算模型进行统一,使得同一套计算逻辑可以同时应用于流处理与批处理两种模式,且最终结果保持一致。此外,流处理与批处理过程中的数据全程存储在同一介质中,即不管采用何种处理模式,数据的流转及存储都在同一介质中完成。
研究背景:
随着互联网、物联网和传感器技术的迅猛发展,数据规模呈现爆发式的增长,其产生频率也越来越高。实时数据源如传感器设备和移动应用持续不断地产生大量数据流,它们具有时序性和即时性的特点,需要被及时处理和分析从而支持即时决策。一方面,传统的批处理方法在处理大规模数据时表现出色,能够较好地完成复杂的数据分析和挖掘任务。然而,这些批处理方法无法满足实时的数据处理和分析需求。另一方面,实时决策也需要综合考虑历史数据,从而让决策更加全面和准确。若针对实时数据处理和历史数据分析分别部署两套系统,不仅显著增加了研发成本和运维成本,还会带来数据不一致的问题。因此需要一种方法来融合实时数据流和历史批处理数据,以实现实时高效和准确可靠的数据处理、分析。基于此背景,数据流批一体化的研究应运而生。
数据流批一体化的研究为实时数据流与历史批处理数据的协同处理提供了技术支持,并推动了大数据分析和应用领域的发展。通过综合利用实时数据流和批处理数据的优势,研究者们致力于开发新的算法和技术,以满足实时数据处理的需求,并提供准确、高效的数据分析和决策支持。此外,在实际应用中,实时数据流和历史批处理数据之间可能存在时间差、数据丢失和数据重复等问题,因此,研究者们还致力于解决数据一致性和完整性的问题,从而获得准确、全面的数据分析结果。
研究概况:
流批一体化技术可以分为数据集成流批一体、数据存储流批一体、物理计算流批一体和逻辑计算流批一体,这些关键要素在如今的数据架构中相互交织,为处理海量数据提供了一种高效、灵活的方式。如图1所示,数据集成流批一体将不同的数据源和数据流整合在一起,集成结果一方面可以对接到存储层,另一方面还可以发送到计算层进行处理。数据存储流批一体则提供了灵活的数据存储机制,它将集成结果数据或者单个数据源的数据有机组织起来,既支持流式数据的实时处理,又能满足批量数据处理的存储需求。物理计算流批一体可以在同一个计算引擎中进行调度,并运行实时数据流和批量数据集的计算任务。逻辑计算流批一体能够提供统一的调用接口,自动选择合适的执行引擎来高效执行各种数据处理任务。
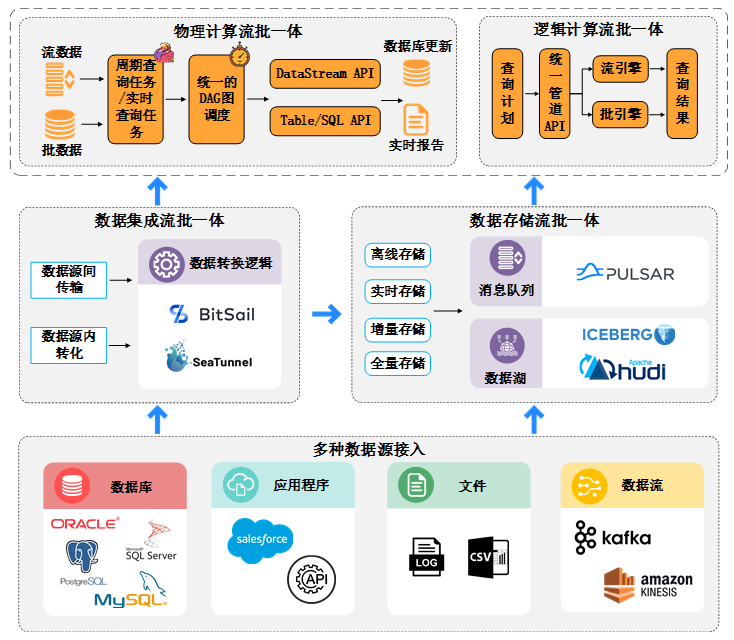
图1 流批一体数据流图
1. 数据集成流批一体:指的是通过数据源间传输和数据源内转换等方式将多种数据源的数据以统一的方式进行采集,并通过数据转换逻辑进行数据的清洗、转换等操作。这样可以既可以减少组件和数据链路的维护成本又可以确保数据的一致性。目前有一些开源产品或平台支持这种模式,例如BitSail[4] 是基于分布式架构的高性能数据集成引擎,支持多种异构数据源间的数据同步,并提供离线、实时、全量、增量场景下的全域数据集成特性。Apache SeaTunnel[5]是一个下一代高性能、分布式、海量数据集成框架,它可以支持多种数据源之间的数据传输和转换,提供简单易用的配置和管理界面,以及丰富的监控功能。
2. 数据存储流批一体:指的是通过离线和实时、全量与增量等方式将数据以统一的格式和结构进行存储,无论是流数据还是批数据,都能在同一个存储引擎中进行读写和访问。这样可以避免数据格式转换的问题,并提供查询加速和联邦查询等能力。目前有一些开源产品或平台支持这种模式,主要可以分为两类,其中一种是消息队列,例如:Apache Pulsar[6],它基于分片存储和灵活消费模型,实现数据的并发访问和无限保存,支持批流一体化的数据处理。另一种则是数据湖,例如Apache Iceberg[7],它是一个开放性表格,可以在分布式文件系统中存储大规模的结构化或半结构化数据,并提供事务性、快照隔离和增量消费等特性;Apache Hudi[8],它可以将数据以增量的形式存储在HDFS、OSS(Object Storage Service)或AWS(Amazon Web Services)等分布式文件系统中,再通过Hive[9]、Spark[10]或Flink[11]等查询层进行实时或离线的分析。
3. 物理计算流批一体:指的是将计算逻辑以统一的编程接口和语言进行开发和执行,无论是流计算任务还是批计算任务,都能在同一个计算引擎中进行DAG图(Directed Acyclic Graph)调度和运行。这样可以降低编程复杂度,保证结果一致性,增加资源利用率。目前有一些开源产品或平台支持这种模式,例如Apache Flink[11],它是一个分布式的流批统一计算框架,可以提供高性能、高可靠和高可扩展的流处理和批处理能力,并支持SQL API、Table API和DataStream API等多种编程范式。Apache Spark[10]是一个流行的开源分布式计算框架,它提供了强大的流处理和批处理能力,并支持多种编程范式,包括SQL API、DataFrame API和RDD API等,支持开发人员使用统一的编程模型进行数据处理和分析。
4. 逻辑计算流批一体:指的是将计算引擎以统一的架构和机制进行设计和实现,无论是流处理还是批处理,都能在同一个运行时管道中进行优化和管理,这样可以避免运行时差异,统一状态管理,提高容错性。目前有一些开源产品或平台支持这种模式,例如Apache Beam[12],它是一个统一的编程模型,可以在不同的执行引擎上运行相同的管道,并提供窗口化、水印、触发器等抽象概念来处理有界或无界的数据集。
未来展望:
流批一体化是大数据领域的一个重要趋势,它可以为企业提供更高效、更灵活、更可靠的数据分析能力,满足不同场景的数据处理需求。随着流批一体化技术的不断发展和完善,可以期待以下几个方面的进步:
(1) 流批一体化的标准化和规范化:目前流批一体化还没有一个统一的标准和规范,不同的产品和平台有不同的实现方式和接口,这给用户带来了一定的学习成本和迁移成本。未来希望有一个通用的流批一体化的标准和规范,可以让用户在不同的产品和平台之间无缝切换和迁移,提高开发效率和兼容性。
(2) 流批一体化的智能化和自动化:目前流批一体化还需要用户手动编写和调优计算逻辑和存储策略,这给用户带来了一定的技术门槛和运维负担。未来希望有一个智能的流批一体化系统,可以根据用户的数据特征和业务需求,自动选择最合适的计算引擎和存储引擎,自动优化计算性能和资源利用率,自动处理数据质量和容错问题,提升用户体验,提高系统稳定性。
(3) 流批一体化的多样化和创新化:目前流批一体化还主要应用于传统的数据分析场景,如指标计算、报表分析、机器学习等。未来希望有一个多样的流批一体化生态,可以支持更多的数据处理场景,包括复杂事件处理、图计算、时空分析等,如在研的START-DB[13]能够同时支持历史时空数据的批量挖掘,以及实时时空数据的流式分析。同时也希望涌现更多新的流批一体化技术,突破现有的技术限制,如支持更高维度的数据查询、提供更丰富的数据交互方式等。
参考文献
[1] Alsurdeh R, Calheiros R N, Matawie K M, et al. Cloud resource provisioning for combined stream and batch workflows[C]//2018 IEEE 37th International Performance Computing and Communications Conference (IPCCC). IEEE, 2018: 1-8.
[2] Carbone P, Katsifodimos A, Ewen S, et al. Apache flink: Stream and batch processing in a single engine[J]. The Bulletin of the Technical Committee on Data Engineering, 2015, 38(4).
[3] S.Benjelloun et al., "Big Data Processing: Batch-based processing and stream-based processing," 2020 Fourth International Conference On Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 2020, pp. 1-6, doi: 10.1109/ICDS50568.2020.9268684.
[4] BitSail. Available online: https://bytedance.github.io/bitsail.
[5] Apache SeaTunnel. Available online: https://seatunnel.apache.org/zh-CN/
[6] Apache Pulsar. Available online: https://pulsar.apache.org/.
[7] Apache Iceberg. Available online: https://iceberg.apache.org/.
[8] Apache Hudi. Available online: Available: https://hudi.incubator.apache.org/.
[9] Apache Hive. Available online: https://hive.apache.org/.
[10] Apache Spark. Available online: https://spark.apache.org/.
[11] Apache Flink: Available online: https://flink.apache.org/.
[12] Apache Beam. Available online: https://beam.apache.org/.
[13] STATR-DB. Available online: https://github.com/Spatio-Temporal-Lab/start-db.
作者介绍
重庆大学
李瑞远
ruiyuan.li@cqu.edu.cn
主要研究领域:时空数据管理与挖掘,分布式计算,城市计算
重庆大学
孙杨洋
sunyangyang@cqu.edu.cn
主要研究领域:流式轨迹数据管理,时空数据挖掘
重庆大学
陈超
cschaochen@cqu.edu.cn
主要研究领域:智能无人系统、普适计算、城市大数据挖掘
京东
鲍捷
baojie@jd.com
主要研究领域:城市计算,时空数据管理与挖掘,分布式计算
北京理工大学
柴成亮
ccl@bit.edu.cn
主要研究领域:数据库、数据湖、数据准备
0 条评论